Blind Search adalah pencarian solusi tanpa adanya informasi yang dapat mengarahkan pencarian untuk mencapai goal state dari current state (keadaan sekarang). Informasi yang ada hanyalah
definisi goal state itu sendiri, sehingga
algoritma dapat mengenali goal state
bila menjumpainya.
Dengan ketiadaan informasi, maka blind
search dalam kerjanya memeriksa/mengembangkan node-node secara tidak terarah dan kurang efisien untuk kebanyakan
kasus karena banyaknya node yang
dikembangkan.
Beberapa
contoh algoritma yang termasuk blind
seacrh antara lain adalah
Breadth
First Search, Uniform Cost Search, Depth First Search, Depth Limited Search,
Iterative Deepening Search, dan Bidirectional Search.
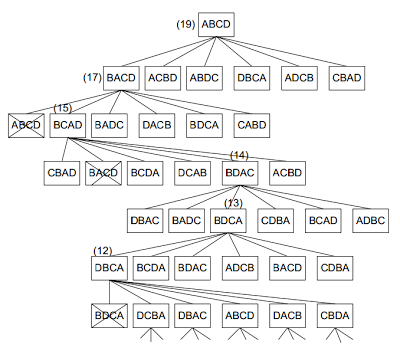
Breadth–First Search
Semua node pada level n akan dikunjungi terlebih dahulu sebelum
mengunjungi node-node pada level n+1. Pencarian dimulai dari node akar terus ke
level 1 dari kiri ke kanan, kemudian berpindah ke level berikutnya dari kiri ke
kanan hingga solusi ditemukan.
Keuntungan
:
- tidak akan menemui jalan buntu, menjamin
ditemukannya solusi (jika solusinya memang ada) dan solusi yang ditemukan pasti
yang paling baik
- jika ada 1 solusi, maka breadth – first search akan
menemukannya,jika ada lebih dari 1 solusi, maka solusi minimum akan ditemukan.
- Kesimpulan : complete
dan optimal
Kelemahan
:
- membutuhkan memori
yang banyak, karena harus menyimpan semua simpul yang pernah dibangkitkan.
Hal ini harus dilakukan agar BFS dapat melakukan penelusuran simpul-simpul
sampai di level bawah
-
membutuhkan waktu
yang cukup lama
CONTOH KASUS:
1. Pada metode
ini diperiksa setiap node pada level yang sama sebelum
mengolah ke level berikutnya yang lebih dalam.
2.
Pencarian dilakukan
pada semua simpul dalam setiap level secara berurutan dari kiri ke kanan.
3.
jika pada
satu level belum ditemukan solusinya, maka pencarian
dilanjutkan pada level berikutnya.
Depth –
First Search
Pencarian
dilakukan pada suatu simpul dalam setiap level dari yang paling kiri.
Jika pada
level yang paling dalam tidak ditemukan solusi, maka pencarian dilanjutkan pada
simpul sebelah kanan dan simpul yang kiri dapat dihapus dari memori.
Jika pada level yang paling dalam tidak ditemukan
solusi, maka pencarian dilanjutkan pada level sebelumnya. Demikian seterusnya
sampai ditemukan solusi.
Keuntungan :
- membutuhkan memori relatif kecil, karena hanya node-node pada lintasan yang aktif saja yang disimpan
- Secara kebetulan, akan menemukan solusi tanpa harus menguji lebih banyak lagi dalam ruang keadaan, jadi jika solusi yang dicari berada pada level yang dalam dan paling kiri, maka DFS akan menemukannya dengan cepat Æ waktu cepat
Kelemahan :
- Memungkinkan tidak ditemukannya tujuan yang diharapkan, karena jika pohon yang dibangkitkan mempunyai level yang sangat dalam (tak terhingga) Æ tidak complete karena tidak ada jaminan menemukan solusi
- Hanya mendapat 1 solusi pada setiap pencarian, karena jika terdapat lebih dari satu solusi yang sama tetapi berada pada level yang berbeda, maka DFS tidak menjamin untuk menemukan solusi yang paling baik Æ tidak optimal.
CONTOH KASUS:
1.
Pencarian dilakukan
pada suatu simpul dalam setiap level dari yang paling kiri.
2. Jika pada level yang terdalam, solusi belum ditemukan, maka pencarian dilanjutkan pada simpul sebelah kanan
dan simpul yang kiri dapat dihapus dari memori
3. Jika pada
level yang paling dalam tidak ditemukan solusi, maka pencarian
dilanjutkan pada level sebelumnya.
4.
Demikian seterusnya sampai
ditemukan solusi
Source
viska.web.id/wp-content/uploads/2012/03/Modul-Pertemuan-2-7.pdf
cs.unsyiah.ac.id/~irvanizam/teaching/ai/INF303-04.pdf
dir.unikom.ac.id/s1-final-project/fakultas...dan...pdf/pdf/4-unikom-d-i.pdf